A Deeper Dive Into Benchmarks

A few weeks ago, we talked about benchmarks. Benchmarks are great for evaluating performance in models, including large language models, embedding models, and classification models. However, benchmarks are not the end-all-be-all and should be further scrutinized. Welcome back to Silatus Weekly. Today, we are going to look at the LLM that could: FinBERT.
Bidirectional Encoder Representations from Transformers
FinBERT is a Bidirectional Encoder Representations from Transformers (BERT) model. BERT models are categorized as embedding models because they generate embeddings from text. If you've read our Silatus blog, you might recall our discussion on the importance of embedding models for Retrieval Augmented Generation (RAG) applications. You can read more about it [here]. For our history and tech enthusiasts, Google pretrained their BERT model on the Books and Wikipedia dataset to improve the accuracy of Google's search engine. BERT matches the user's query with the most relevant search results based on context.

Pretraining models involves initializing a transformer-based neural network architecture with many layers. After pre-training, organizations fine-tune their models on task-specific datasets for tasks such as text summarization, translation, and question-answering. In a sense, pretraining creates the foundation of knowledge for a model, whereas fine-tuning refines it to excel at a specific task. Think of it as going to school to learn the fundamentals, and then going to college to specialize in your chosen domain.

FinBERT is a Bert model fine tuned on financial data. In the paper "Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics?" A Study on Several Typical Tasks" The research compared various language models including FinBERT, ChatGPT, and GPT-4 on their capability to analyze financial texts. The assessment spanned several tasks such as Named Entity Recognition (NER), sentiment analysis, and numerical reasoning within financial contexts, using a range of datasets tailored for these specific functions.
In certain areas, FinBERT demonstrated better performance. Specifically, in tasks demanding deep domain knowledge such as sentiment analysis, FinBERT's specialized training on financial language allowed it to excel, reflecting its effectiveness in contexts closely aligned with its training data. While there is a case to be made domain-specific models in handling tasks that benefit from nuanced understanding of sector-specific language and concepts, we need to futher examine the comparison.
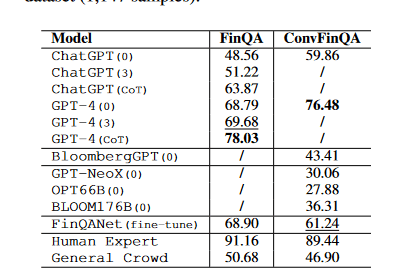
False Comparison
BERT and GPT-4 are indeed distinct models designed for different purposes within the field of natural language processing. BERT, which stands for Bidirectional Encoder Representations from Transformers, is primarily designed to understand the context of a word within a text by considering the words that come before and after it. This makes it particularly adept at tasks that require a deep understanding of language context, such as Named Entity Recognition (NER) and sentiment analysis. BERT models excel in classifying, segmenting, and interpreting text.
On the other hand, GPT-4, which is the fourth-generation Generative Pre-trained Transformer, is designed with a focus on generating coherent and contextually relevant text. It can perform a wide array of NLP tasks, including NER and sentiment analysis, but its main strength lies in its ability to create text that is indistinguishable from that written by humans.
Comparing BERT and GPT-4 directly on tasks like NER or sentiment analysis can be misleading, as they are optimized for different aspects of language processing. BERT's architecture is finely tuned for analyzing and understanding language, while GPT-4's capabilities shine in generating language. This distinction is important when considering the best tool for a specific NLP task, as the choice between BERT and GPT-4 would depend on whether the task requires deep language understanding or advanced text generation.
Its great seeing papers, show the strength and weakness of different models. However, when we see claims on the web stating "Model X did better than GPT-4", we need to see if its fair statement. No where in the paper did the paper state these claims but social medical tends to skew the narrative. With that said, its quite possible an open-source LLM will out perform GPT-4 in the near future.
Silatus AI helped to write this article.
Read more…



